Compilers@NJUSE-Chapter01 Introduction
什么是编译器
编译器
- 一个编译器是一个程序
- 读入源语言编写的程序,并把该程序翻译成一个等价的、用目标语言编写的程序

- 若翻译后的程序为可执行机器语言程序,则可被调用以处理输入

- 若翻译过程发现源程序有错,则报错
- 狭义:程序设计语言 -> 机器代码
- 广义:程序变换 C++ -> C -> 汇编 Pascal -> C
编译器 vs 解释器
编译器
- 效率高,一次编译,多次运行
- 通常目标程序可执行
解释器
- 直接利用用户的输入,执行源程序中的操作

- 不生成目标程序,而实根据源程序的语义直接运行
- 边解释,边执行,错误诊断效果好
Java、Python均有编译器
Java
Java结合了编译器和解释器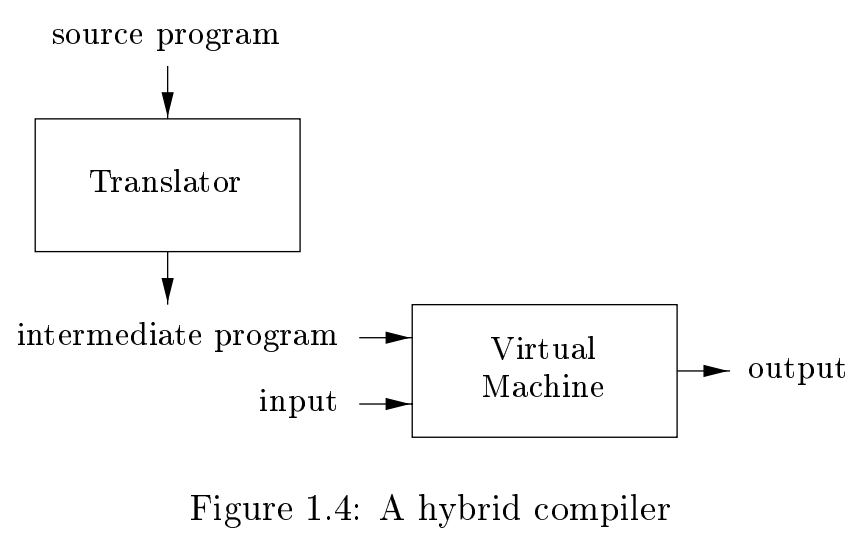
- 先编译成字节码,再由Java虚拟机解释执行
- 即时编译(Just-in-time compiling)
典型语言(如C)的编译

- 预编译器
- 编译器
- 汇编器
- 链接器
- 加载器
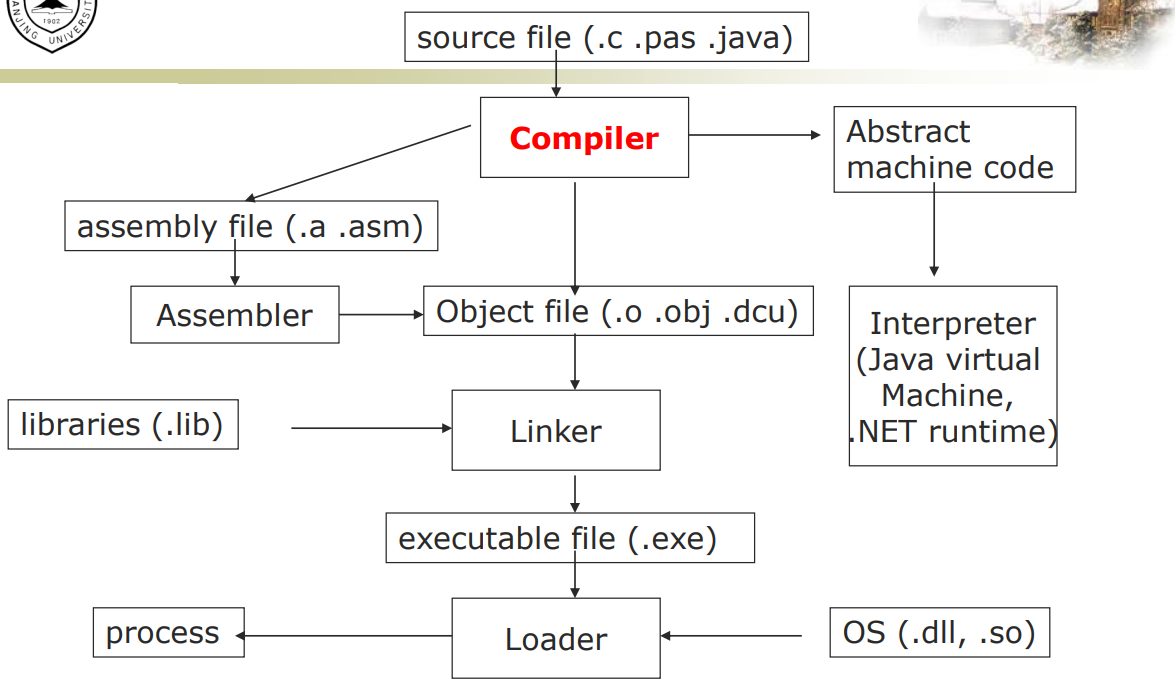
编译器的结构
Overview
分析部分(Analysis)
- 源程序-语法结构-中间表示
- 搜集源程序中的相关信息,放入符号表
- 分析、定位程序中可能存在的错误信息(语法、语义错误)
- 又称编译器的前端(front end),是与机器无关的部分
综合部分(Synthesis)
- 根据符号表和中间表示构造目标程序
- 又称编译器的后端(back end),是与机器相关的部分、
编译器中的若干步骤
- 每个步骤把源程序的一种表示方式转换成另一种表示方式
- 实践中,某些中间表示不需要明确构造出来
- 符号表可由各个步骤使用

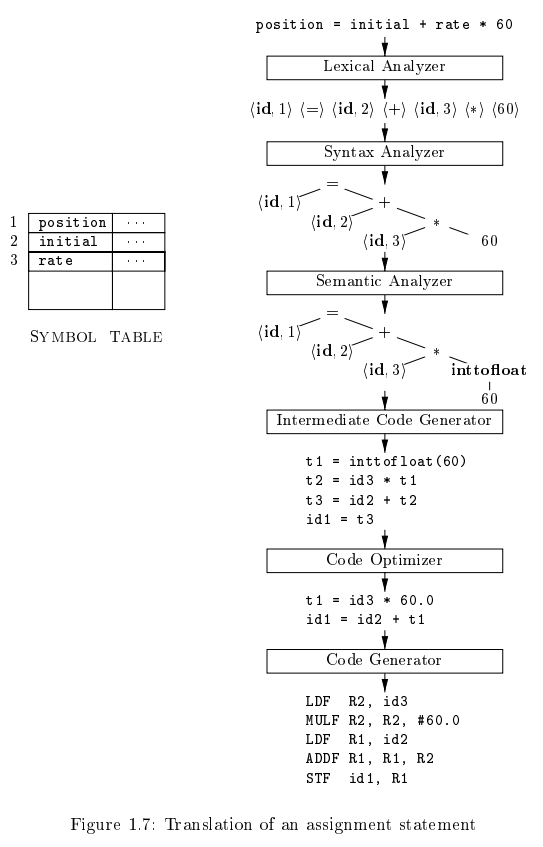
词法分析
词法分析/扫描(lexical analysis or scanning)
- 读入源程序的字符流,输出有意义的词素(lexeme)
- 基于词素,产生词法单元(token):
- token-name由语法分析步骤使用
- attribute-value属性值指向相应的符号表条目,由语义分析/代码生成步骤使用
例子
position = initial + rate * 60
position为一个词素,将被映射为token<id, 1>,其中,id是一个表示表示标识符identifier的抽象符号,1则指向符号表中position对应的条目。一个标识符对应的符号表条目存放该标识符有关的信息,如它的名字和类型=为一个词素,为映射为token<=>。由于该token不需要attribute-name,可直接省略该部分。initial是一个词素,被映射为token<id, 2>,其中2指向符号表中initial对应的条目+是一个词素,被映射为token<+>rate是一个词素,被映射为token<id, 3>,其中3指向符号表中rate对应的条目*是一个词素,被映射为token<*>60是一个词素,被映射为token<60>
上述例子中语句翻译的过程
语法分析
语法分析后,需要得到词素序列的语法结构
语法分析/解析(syntax analysis or parsing)
- 根据各个词法单元的第一个分量来创建树形中间表示形式。通常是语法树(syntax tree)
- 树中的每个内部结点表示一个运算
- 该结点的子节点表示该运算的分量
- 指出了词法单元流的语法结构
语义分析(semantic analysis)
得到语义(meaning),对于编译器来说比较难
语义分析(semantic analysis)
- 使用语法树和符号表中的信息,检查源程序是否满足语言定义的语义约束
- 同时收集类型信息,将信息存放在语法树或符号表中,用于中间代码生成
- 类型检查,自动类型转换
上文例子中的词素60即进行了类型转换(从整数转换为浮点数)
中间代码生成
根据语义分析的输出,生成类机器语言的中间表示
三地址代码:
- 由一组类似于汇编语言的指令组成
- 每个指令最多包含三个运算分量
- 每个运算分量都像一个寄存器
- 上例中的中间代码生成器的输出为三地址代码序列

关于三地址指令
- 每个三地址赋值指令的右部最多只有一个运算符,因此这些指令确定了运算完成的顺序
- 编译器应该生成一个临时名字以存放一个三地址指令计算得到的值
- 有些三地址指令的运算分量少于三个
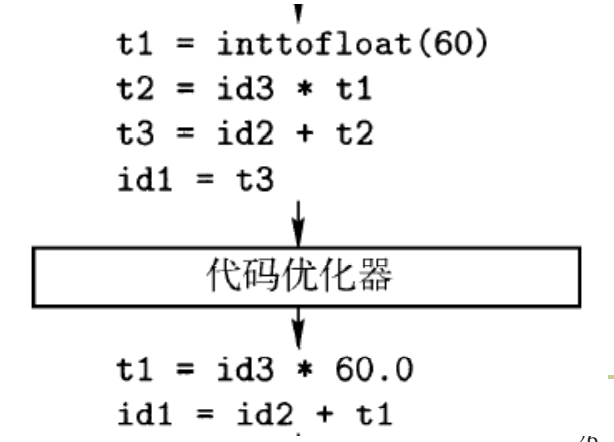
代码优化
通过对中间代码的分析,改进中间代码,得到更好的目标代码
- 快、短、能耗低
- 上例可以进行优化
代码生成
- 把中间表示形式映射到目标语言
- 寄存器的分配
- 指令选择
- 内存分配
- 上例会被翻译为机器代码

符号表管理
- 记录源程序中使用的变量的名字,收集各种属性
- 名字的存储分配
- 类型
- 作用域
- 过程名字的参数数量、参数类型
- 传参方法(如值传参或引用传参)
- 返回值类型
- 符号表可由编译器的各个步骤使用
- 可以允许编译器快速找到每个变量名称的记录,并可以快速存储、检索数据
将多个步骤组合成趟(pass)
- 趟:以文件为输入输出单位的编译过程的个数,每趟可由一个或若干个步骤构成
- 如:前端步骤中的词法分析、语法分析、语义分析、以及中间代码生成可以被组合在一起成为一趟
- 代码优化可以作为一个可选的趟
- 有一个为特定目标机生成代码的后端趟
- “步骤”是逻辑组织方式
- “趟”和具体的实现相关
- 参考LLVM实现中的Pass
编译器构造工具
- 语法分析器的生成器: yacc/bison
- 根据一个程序设计语言的语法描述自动生成语法分析器
- 扫描器的生成器: lex/flex
- 根据一个语言的词法单元的正则表达式描述生成词法分析器
- 语法制导的翻译引擎
- 生成一组用于遍历分析树并生成中间代码的程序
- 代码生成器的生成器
- 把中间语言的每个运算翻译成目标机上机器语言的规则,生成代码生成器
- 数据流分析引擎
- 收集数据流信息,用于优化
- 编译器构造工具集
- 提供了可用于构造编译器的不同阶段的例程的完整集合
编译技术的应用
- 高级程序设计语言的实现
- 高级程序设计语言的抽象层次的提高有利于编程,但是直接生成的代码却相对低效率
- 聚合类型/高级控制流/面向对象/垃圾自动收集机制
- 针对计算机体系结构的优化
- 并行性:指令级并行,处理器层次并行
- 内存层次结构
- 新体系结构的设计
- RISC
- 专用体系结构
- 一个新的体系结构特征能否被充分利用,取决于编译技术
- 程序翻译
- 二进制翻译/硬件合成/数据查询解释器/编译后模拟
- 软件生产率工具
- 类型检查
- 边界检查
- 内存管理工具
程序设计语言
分类
- 语言的代分类
- 第一代语言:机器语言
- 第二代语言:汇编语言
- 第三代语言:高级程序设计语言
- Fortran, Pascal, Lisp, Modula, C
- 第四代:特定应用语言:NOMAD, SQL, Postscript
- 第五代:基于逻辑和约束的语言,Prolog、OPS5
- 命令式语言/声明式语言
- 前者指明如何完成,后者指明要完成哪些计算
- 冯.诺依曼语言/面向对象的语言/脚本语言
- 面向对象语言
- Simula, Smalltalk, Modula3, C++, Object Pascal, Java, C#
- 数据抽象、继承
程序设计语言和编译器之间的关系
- 程序设计语言的新发展向编译器设计者提出新要求
- 设计相应的算法和表示方法来翻译和支持新的语言特征
- 通过降低高级语言的执行开销,推动这些高级语言的使用
- 编译器设计者还需要更好地利用新硬件的能力
基础概念
- 静态/动态
- 静态:语言策略支持编译器静态决定某个问题
- 动态:只允许在程序运行时刻做出决定
- Java类声明中的static指明了变量的存放位置可静态确定
- 作用域
- x的一个声明的作用域是指程序中的一个作用域
- 静态作用域:通过静态阅读程序决定作用域
- 动态作用域
- 环境与状态
- 环境:是从名字到存储位置的映射
- 状态:从内存位置到它们的值的映射
- 环境的改变需要遵守语言的作用于规则
- 静态作用域和块结构
- C族语言使用静态作用域
- C语言程序由顶层的变量、函数声明组成
- 函数内部可以声明变量(局部变量/参数),这些声明的作用域在它出现的函数内
- 一个顶层声明的作用域包括其后的所有程序。除去那些具有同样名字的变量声明的函数体
- 作用域规则基于程序结构,声明的作用域由它在程序中的位置隐含决定
- 也可通过public、private、peotected决定
- C族语言使用静态作用域
- 动态作用域
- 对一个名字x的使用指向的是最近被调用但还没有终止且声明了x的过程中的这个声明
- 参数传递机制
- 值调用 (call by value):对实在参数求值/拷贝,再存放到被调用过程的形参的内存位置
- 引用调用(call by reference):实际传递的是实在参数的地址
- 名调用:早期使用,现在已经基本废弃
- 别名(引用)
- 别名:两个指针指向同一个位置的情况
- 导致看起来不同的形式参数实际上是对方的别名
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Rashawn's Blog!